
Le mode de rétention de vos données peut vous sembler secondaire, mais ne vous y trompez pas, il a un impact direct sur la sécurité de vos données.
Définition de la rétention
En clair, cela signifie qu’un logiciel de sauvegarde de données va conserver plusieurs versions de vos données constituant un historique des modifications : c’est ce que l’on appelle la rétention.
Rétention par nombre de versions
La rétention basée sur un nombre de versions fonctionne de la façon suivante :
- Chaque fois qu’un fichier est sauvegardé, il est référencé comme une nouvelle version.
- Si le nombre de versions du fichier dépasse le nombre de versions autorisées, la version la plus ancienne est supprimée.
Cette méthode est extrêmement simple à comprendre et à implémenter : c’est au moment de la sauvegarde que le logiciel va gérer la purge des anciennes version.
Rétention temporelle
La logique de la rétention temporelle des données de sauvegarde est différente. Elle n’est non plus basé sur un nombre de version fini, mais sur des étapes temporelles.
Vous pouvez par exemple décider de garder toutes les versions de vos fichiers pendant une semaine, puis une seule version par semaine pendant un mois, puis une version par mois pendant 3 mois, etc…
Le processus de « purge » de données est donc différent :
- Chaque fois qu’un fichier est sauvegardé, il est horodaté.
- A une fréquence donnée, les serveurs de stockage vont scruter les versions disponibles du fichier et en fonction des règles temporelles établies (x versions par semaine, plus ancien que y mois, etc…), certaines versions pourront êtres supprimées.
Cette méthode, plus complexe à comprendre et à implémenter, permet d’obtenir un vieillissement plus homogène et granulaire des données.
Exercice pratique
Imaginons que nous ayons deux logiciels de sauvegarde différents :
- Un logiciel A, qui utilise une rétention temporelle selon le modèle suivant :
- Au bout d’une semaine, on ne conserve au maximum qu’une version par semaine
- Au bout de quatre semaines, on ne conserve aucune ancienne version
- Un logiciel B, qui utilise une rétention par version sur 10 versions
Notre sélection de fichiers contient deux fichiers :
- Un fichier très critique « 1 », modifié et sauvegardé 3 fois par jour
- Un fichier peu critique « 2 », modifié et sauvegardé 1 fois toutes les deux semaines
Le graphique ci-dessous représente la durée de rétention en jours pour chaque fichier et avec chaque méthode :
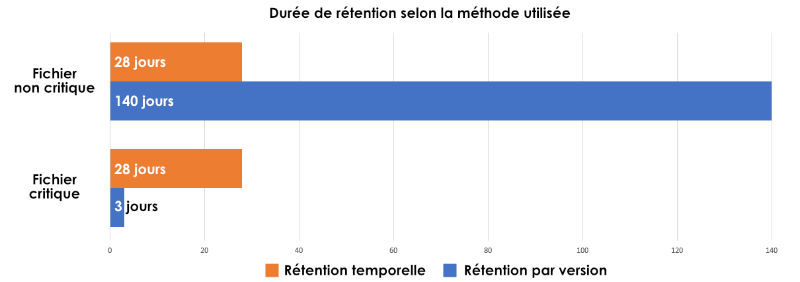
Avec une rétention par nombre de versions, on constate que :
- Le fichier 1 qui est très critique a une rétention réelle de moins d’une semaine
- Le fichier 2 qui est peu critique a une rétention d’environs 5 mois
Avec une rétention temporelle, le constat est très différent :
- Le fichier 1 (très critique) a une rétention de quatre semaines, avec la possibilité de restaurer toutes les versions sur la première semaine
- Le fichier 2 (peu critique) a une rétention de quatre semaines, avec la possibilité de restaurer deux versions
Cela laisse clairement apparaître la faiblesse de la rétention par nombre de version : plus vos données sont critiques et modifiées fréquemment, moins la rétention est importante.
Plus simplement, la durée de rétention avec le mode « par versions » est inversement proportionnelle à la criticité du fichier ! Imaginez un tel système couplé à une sauvegarde continue des données…
Notre position
Lors du choix d’une offre de sauvegarde, il faut être particulièrement vigilant sur ce point technique.
Un mauvais choix vous empêcherait clairement de restaurer des données exploitables en cas de problème. Surtout que certains acteurs vous propose, sans aucune possibilité de paramétrage de votre part, une rétention limitée à… 3 version !
Lors de la conception de notre solution de sauvegarde, nous avons choisi d’implémenter une rétention temporelle afin de pouvoir vous assurer une sécurité et une « restaurabilité » optimales.
De plus, vous êtes totalement libre de paramétrer la stratégie de rétention de vos données : nombre de tranches de temps, durées des tranches, durée totale… C’est la solution qui s’adapte à vous, pas le contraire !
Enfin, il est légitime de se poser la question de l’impact de l’historique sur le volume de stockage. Concrètement, avec un mode incrémental par blocs associé à un bon algorithme de déduplication des données à la source, l’impact sur le volume de stockage est extrêmement faible.
N’hésitez plus, contactez-nous pour en discuter !




